Offline-First Mobile Apps: Why They Matter for High-Altitude and Rural Networks
Most mobile applications built today make a dangerous assumption: constant, high-speed internet. When a user opens an app, they expect immediate data loading from external servers, but in high-altitude regions like Leh, Ladakh, Spiti, or the remote hill stations of Uttarakhand, this assumption leads to complete application failure. For local business owners, tour operators, and agricultural cooperatives, a standard app that stalls on slow networks represents lost bookings, frustrated users, and zero operational utility.
To succeed in these environments, software architects must build using an offline-first strategy. Offline-first development is not merely a technical configuration; it is the fundamental baseline for regional digital success. This technical blueprint explains why offline architectures are crucial, the core tools required, and how to build a highly resilient synchronization engine for unstable networks.
📁 Table of Contents
- 👉 The High-Altitude Connectivity Challenge in India
- 👉 The Tech Stack of Resilient Offline-First Mobile Apps
- 👉 How to Architect an Offline Synchronization Engine
- 👉 Real-world Case Studies: Driving Business Survival
- 👉 Frequently Asked Questions (FAQ)
- • Offline-First App Development Cost
- • Handling Data Conflict Resolution
- • Large Media Files Storage Strategy
- • Room and SQLite Sync over Weak Connections
- • CRDTs vs Last-Write-Wins vs MVCC
- • Resilient Intermittent Connectivity Queues
- • Bandwidth Optimization & Payload Formats
- • Chunked Media Uploads on 2G/3G
The High-Altitude Connectivity Challenge in India
High-altitude geography severely restricts cellular infrastructure. Extreme topography causes major physical signal blocks, while freezing winter temperatures damage base stations. In regions like Ladakh, mobile data speeds fluctuate rapidly, dropping from 4G to 2G or cutting out entirely for hours at a time. Testing shows that over 70% of standard web request timeouts occur in these rural networks due to severe packet loss and extremely high ping latencies (often exceeding 3,000 milliseconds).
When a conventional application attempts to fetch database values over these connections, the application main thread freezes. The loading wheel spins indefinitely until a gateway timeout terminates the connection. For an adventure tourism agency running a motorcycle trip through the Khardung La pass, an online-only booking or checkout screen is completely useless. The app must be engineered to expect zero network access, treating active internet connectivity as an occasional performance optimization rather than a hard dependency.
The Tech Stack of Resilient Offline-First Mobile Apps
To design an offline-first mobile app, you must select local database systems that write and query data directly on the physical mobile device, bypassing network requests entirely. When the phone establishes a network connection, a background sync engine processes data exchanges with the central server fluidly.
For cross-platform frameworks like React Native and Flutter, developers have several excellent local storage engines to choose from:
| Local Database Engine | Primary Architecture | Ideal Use Case | Himalayan Network Suitability |
|---|---|---|---|
| SQLite / WatermelonDB | SQL / Relational Schema | React Native apps with complex relational data models. | Highly suitable. Fast local query performance on low-spec Android devices. | Hive | NoSQL / Key-Value Store | Flutter apps requiring simple, lightweight local storage. | Excellent. Written natively in Dart, zero native dependencies, extremely fast. |
| Realm (MongoDB) | Object-Oriented Schema | High-scale applications requiring automated server syncing. | Good, but requires careful configuration to avoid battery drain on weak signals. |
By utilizing local-first storage engines like Hive or SQLite, your mobile applications load data in under 20 milliseconds, providing a lightning-fast experience regardless of cellular signal strength. For a comparative study of building cross-platform apps on a budget, explore our detailed analysis of Flutter vs React Native in 2026.
How to Architect an Offline Synchronization Engine
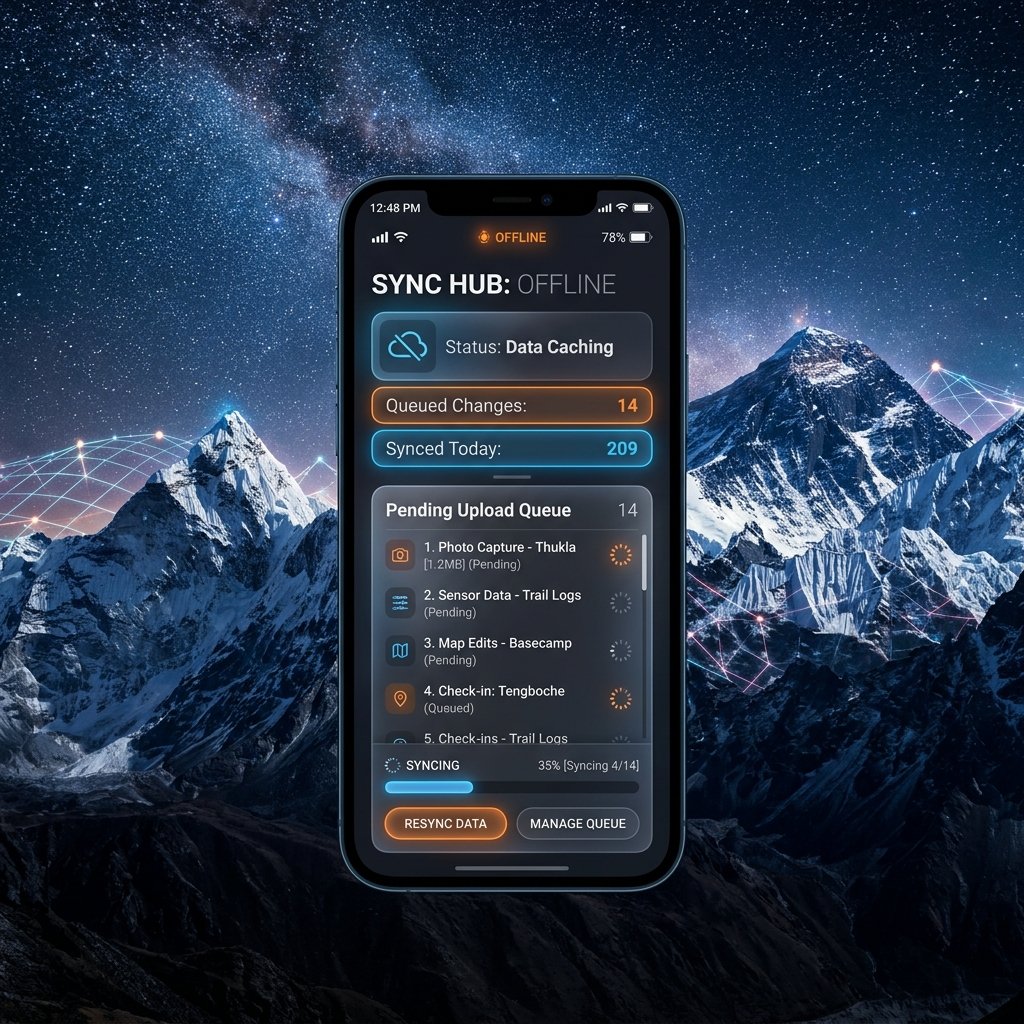
An offline-first app's heart is its synchronization engine. The local database manages every user interaction (writing, reading, searching) instantly. Meanwhile, a background queue handles the complex process of syncing this local state with your central cloud database.
Here is how a reliable offline-first synchronization flow operates:
- The Local Outbox Queue: Every write operation performed by the user is not sent directly to the server. Instead, it is serialized as a JSON transaction payload and appended to a local "Outbox" database table.
- Network Status Monitoring: The app utilizes active network observers (like NetInfo) to monitor network state changes. Crucially, the app must not assume that a "connected" status means a working connection. The sync engine should perform a rapid, lightweight ping check to confirm actual internet access.
- Sequential Sync Execution: Once actual connectivity is confirmed, the sync engine reads the local Outbox table sequentially. It processes transactions in strict order to maintain data integrity.
- Idempotency Keys: If a sync request is sent but the connection drops before the server can return a confirmation, the sync engine will retry when connection returns. To prevent duplicate database records on the server, every transaction must carry a unique, locally generated UUID as an idempotency key.
// Example of a local offline Outbox transaction structure
{
"transactionId": "9b1deb4d-3b7d-4bad-9bdd-2b0d7b3dcb6d",
"action": "CREATE_BOOKING",
"payload": {
"riderName": "Tsering Dorje",
"tourId": "himalayan-bullet-tour-2026",
"startDate": "2026-07-15",
"bookingAmount": 45000
},
"status": "pending",
"createdAt": "2026-05-28T16:34:00Z"
}
This localized data model guarantees that your operations are never blocked by poor network. Users can comfortably fill out forms, register data, and request services in the middle of a remote mountain pass, confident that their changes are safely recorded locally and will synchronize once they return to a connected hub.
Real-world Case Studies: Driving Business Survival
We applied this offline-first design to several digital projects in Northern India. In one instance, a regional cooperative handling dry fruit logistics across remote valleys required an app to track inventory at collection hubs. By implementing an offline-first React Native architecture with SQLite, the field staff could catalog thousands of kilograms of produce inside zero-signal storage depots without experiencing a single app crash.
In another case study, we built a custom booking flow for a premium motorcycle tour operator in Leh. By ensuring their mobile application functioned entirely offline, their tour leaders could easily verify passenger details, check route plans, and record emergency fuel logs at high-altitude passes. This direct, highly reliable design process matches the core philosophy behind our custom commission-free travel portals, which you can read about in our detailed review of building a WhatsApp-first booking system for tour operators in Ladakh.
Frequently Asked Questions
Does building an offline-first app double the development cost?
A common misconception among business owners and startup founders in India is that building an offline-first architecture doubles the development timeline and budget. In reality, it does not. When architected correctly from day one, an offline-first approach typically adds only 15% to 20% to the total Minimum Viable Product (MVP) budget. This is because modern cross-platform mobile frameworks like Flutter and React Native feature highly mature local databases (such as SQLite, WatermelonDB, and Hive) that simplify local reading and writing.
By leveraging pre-built synchronization utilities and libraries, developers do not need to invent sync mechanics from scratch. Instead, the effort shifts from writing complex network-handling code (with infinite try-catch loops, timeout listeners, and custom retry logic scattered across the UI) to structuring a clean, unified data access layer. In fact, by eliminating the need to block the user interface for every API call, frontend development is often faster and less error-prone. The marginal increase in cost is concentrated entirely in the initial database schema design, setting up the local queue table, and writing the idempotent server endpoints. When weighed against the cost of losing up to 50% of your user base due to application crashes and loading timeouts on remote Himalayan networks, this minor upfront investment is the most reliable decision a business can make.
How do offline-first applications handle data conflict resolution?
Data conflict resolution is the cornerstone of a functional offline-first application. When an app allows users to modify data offline, there is always a chance that the same record is updated by another user or an automated background process on the server before the local changes sync. The most reliable conflict resolution method depends heavily on the business domain and user collaboration needs:
- Last-Write-Wins (LWW): This is the simplest and most common strategy for single-user apps or simple CRUD systems. The synchronization engine compares timestamps on the conflicting records, and the update with the most recent timestamp overwrites the older version. While highly efficient, LWW requires extremely accurate client and server clock synchronization using Network Time Protocol (NTP) to prevent timezone drift or client-side tampering from corrupting data.
- Field-Level Merging: Instead of overwriting the entire database row, the server analyzes which specific fields changed. For instance, if user A updates a guest's email address offline while user B updates their phone number, the server merges the changes into a single updated record since the updates do not overlap. This provides a seamless user experience with minimal data loss.
- Conflict-Free Replicated Data Types (CRDTs): For highly collaborative environments, such as a shared inventory list or joint booking sheet used by multiple guides on a trek, we implement CRDTs. CRDTs are mathematical data structures that automatically merge concurrent modifications without requiring a central coordinator, guaranteeing that all nodes converge to the exact same state once they sync.
Can offline-first apps handle large media files like photos?
Yes, offline-first mobile applications can efficiently manage large media files, including photos, PDF receipts, and video logs, even on highly unstable networks. The key is to never store raw binary media files directly inside your relational database (SQLite or Room), as doing so dramatically increases database size and degrades query performance. Instead, we implement a hybrid storage architecture:
- Local File System Storage: The actual image or file is saved directly into the mobile device’s secure local storage directory. The database table only stores a lightweight, unique string referencing the local file path (e.g.,
file:///data/user/0/com.bkbtechies/files/receipt_983.jpg). - Client-Side Processing: Before the file is placed in the sync queue, the app automatically runs a compression and resizing routine. For instance, a 12-megapixel raw photo is downsampled to a 1080p WebP image, reducing the file size from 6MB to under 300KB without losing visible quality. This compression makes uploading over a weak 2G or 3G connection feasible.
- Background Queue Syncing: The sync engine registers a background upload task with the operating system. Crucially, the app can be configured to hold large media uploads in the local outbox until the device detects a stable Wi-Fi connection, or run resumable, chunked HTTP uploads that can pick up exactly where they left off if a cellular signal drops midway.
How do Room and SQLite handle transactional database synchronization over highly unstable networks without corrupting the local cache?
Maintaining database integrity on a mobile device when cellular connections are constantly dropping requires strict transactional guarantees. In native Android development, Room acts as an abstraction layer over SQLite, providing powerful tools to ensure your local cache remains uncorrupted, even during sudden network drops, battery depletions, or app process crashes. This reliability is achieved through several core architectural mechanisms:
First, Room utilizes Write-Ahead Logging (WAL) mode in SQLite. In standard rollback journal mode, writing to the database completely locks it, preventing any read operations from occurring simultaneously. Under WAL mode, SQLite writes new transactions to a separate WAL file rather than directly modifying the main database file. This allows background synchronization services to perform intense database writes in the background while the UI thread continues to read and render local data with zero stutter or lag. If a network call drops mid-sync, SQLite's transactional rollback guarantees that the database returns to its last known consistent state automatically, leaving no partially written or corrupted records.
Second, we wrap all synchronization routines in atomic database transactions using the @Transaction annotation in Room DAOs. When the app receives a batch sync payload from the server, the entire operation is treated as a single unit of work. If the transaction contains 100 rows, and a cellular failure occurs on the 99th row, the database rolls back the entire batch, preventing half-applied states. Furthermore, to avoid primary key collisions when clients insert rows offline, we avoid auto-incrementing integers. Instead, every record is assigned a universally unique identifier (UUID) generated locally on the device using secure random number generators. This ensures that records created offline will never conflict during the database synchronization phase.
What are the best conflict resolution strategies (e.g., CRDTs vs. Last-Write-Wins vs. MVCC) for offline-first enterprise applications?
In enterprise-grade offline-first applications, handling synchronization conflicts is a major design consideration. When multiple users operate offline in remote locations—such as two logistics managers editing cargo quantities in different valleys—they will inevitably modify the same resource simultaneously. Choosing the right conflict resolution strategy requires balancing engineering complexity against business data accuracy requirements.
| Strategy | Mechanism | Pros | Cons |
|---|---|---|---|
| Last-Write-Wins (LWW) | Compares timestamps; the latest update overwrites previous ones. | Easiest to implement, very low CPU and memory overhead. | Prone to data loss if user device clocks drift or are set incorrectly. |
| Multi-Version Concurrency (MVCC) | Tracks revision trees (e.g., PouchDB). Conflicting branches are flagged for manual or programmatic merge. | Zero data loss; retains full edit history and context. | High storage overhead; requires complex UI logic for conflict resolution. |
| Conflict-Free Replicated (CRDTs) | Mathematical structures (like Yjs or Automerge) that merge automatically without a central server. | Seamless, automatic merging of collaborative text and state. | Extremely complex to architect; significantly higher payload sizes. |
For most logistics, booking, and field operations, Multi-Version Concurrency Control (MVCC) combined with server-side business rules is highly recommended. For example, if a tour operator receives two offline bookings for the last available motorcycle, instead of discarding one using Last-Write-Wins, MVCC preserves both records, flags a conflict, and triggers an automated notification to the support team to manually allocate a backup motorcycle. This approach ensures complete operational visibility and prevents silent, catastrophic data loss.
How do you design a resilient intermittent connectivity queue that survives app crashes and device reboots?
An offline-first application cannot rely on volatile in-memory queues to store outgoing transactions. If the user performs an action in a zero-connectivity zone and the app process is subsequently terminated by the operating system to reclaim RAM, or if the device runs out of battery, all unsynced data would be permanently lost. To build a highly resilient sync queue, developers must implement the Persistent Outbox Pattern.
Under this pattern, every write operation (creating a booking, updating inventory, recording an inspection) is executed locally on the SQLite database, and simultaneously, a serialized version of the transaction is written to a local outbox_queue database table. This outbox table stores the transaction ID (UUID), target API endpoint, payload JSON, creation timestamp, retry count, and synchronization status (e.g., PENDING, FAILED). Because this table is persisted directly to the physical storage, the queue remains completely intact regardless of app state, operating system crashes, or device reboots.
To orchestrate the background execution of this queue, we utilize OS-level task schedulers—specifically WorkManager on Android and BackgroundTasks on iOS. WorkManager is designed to be highly resilient; it stores its task scheduling metadata inside its own internal SQLite database. When scheduling a sync task, we apply strict execution constraints:
// Theoretical configuration for resilient background sync scheduling
const syncConstraints = {
networkType: NetworkType.CONNECTED,
requiresBatteryNotLow: true
};
WorkManager.enqueueUniqueWork(
"BackgroundSyncJob",
ExistingWorkPolicy.KEEP, // Prevent redundant active workers
syncConstraints,
backoffPolicy: BackoffPolicy.EXPONENTIAL,
initialDelay: 15000 // 15 seconds initial retry delay
);
By defining an exponential backoff policy, we prevent the client application from constantly hammering the API servers when there is no internet routing, saving battery and bandwidth. Once a stable connection is detected, WorkManager wakes up the sync worker, processes the outbox queue sequentially in the order records were created, and marks items as SYNCED only after receiving a 200 OK response with a matching idempotency key from the backend server.
Which payload formats and bandwidth optimization techniques (e.g., JSON Patch vs. Protocol Buffers) are most effective for extremely low-bandwidth networks?
In high-altitude areas like Leh or remote villages across Spiti Valley, mobile connections are not just unstable; they are often limited to 2G or 3G speeds with high packet loss. Under these conditions, sending large, verbose JSON payloads is a recipe for synchronization failure. The larger the payload, the higher the probability that a connection drop will occur during transmission, forcing a full retry and consuming precious client data.
To optimize bandwidth, architects have two primary levers: payload format optimization and sync delta modeling. Traditional JSON, while human-readable and standard, is extremely verbose and redundant due to repeating keys and text formatting. By replacing JSON with binary serialization formats like Protocol Buffers (Protobuf) or MessagePack, you can reduce the raw payload size by 60% to 80%. Protobuf compiles schemas into highly compact binary formats where field names are replaced by small integer markers, making the data stream incredibly lightweight. MessagePack offers a schema-less alternative that converts standard JSON objects directly into compressed binary arrays, requiring zero modification to existing backend databases.
Beyond serialization, implementing Delta Synchronization is crucial. Instead of uploading the entire state of a document or record during every sync cycle, the application should only transmit the changes (deltas). We achieve this by conforming to the JSON Patch (RFC 6902) standard. A JSON Patch payload represents the exact operations (such as add, remove, or replace) required to transform the server's data state to match the client's new state. For example, updating a rider's phone number on a massive tour booking object is reduced from a 15KB full-object transfer to a tiny 120-byte patch request. Combined with Brotli or GZIP compression at the network layer and HTTP/3 header compression, this delta-sync pattern ensures that synchronization succeeds even over dial-up speeds.
How should offline-first apps handle complex media uploads and large binary assets on slow 2G/3G connections?
Uploading complex media files—such as high-resolution photographs of delivery parcels, scanned documents, or trekking trail logs—on a slow and dropping cellular network is one of the most challenging problems in mobile development. Attempting a standard single-part HTTP POST upload for a 5MB image on a 2G network will fail nearly 95% of the time. To solve this, we engineer a robust, fault-tolerant binary upload pipeline.
The first line of defense is aggressive client-side pre-processing. The raw media captured by the device's camera must be compressed before it ever enters the sync queue. Using native image processing APIs, we downscale the resolution to a maximum of 1920x1080 and transcode the format to highly efficient WebP (for images) or H.265 (for videos). This immediately slashes the file size from several megabytes to a highly manageable 250KB to 400KB range.
For the actual transfer, we implement Resumable Chunked Uploads. Rather than sending the file in one continuous request, the sync worker splits the binary file into small, uniform chunks (e.g., 128KB or 256KB each). The app uploads these chunks sequentially using an open-source resumable protocol like TUS (tus.io). The server tracks which chunks have been received and provides an offset value. If the network drops at chunk 3 of a 4-chunk upload, the client sync engine does not restart the upload from the beginning. Instead, when connectivity resumes, it queries the server for the current offset and only uploads chunk 4. This chunked approach reduces data waste to near-zero and ensures that even the largest media files eventually sync successfully over highly compromised connections.
Targeting Customers in Low-Connectivity or High-Altitude Regions?
Don't lose your regional user base to slow loading and network timeouts. Let BKB Techies design a highly reliable offline-first mobile app engineered to survive under extreme connectivity constraints.